For the better part of a decade, the default answer to enterprise data infrastructure was a single platform: Snowflake for analytics-heavy organizations, Databricks for ML-forward ones, or both for companies large enough to afford the overlap. These platforms earned their position. They abstracted away enormous complexity, delivered strong performance, and let data teams focus on queries and models instead of infrastructure plumbing.
But something has shifted. Across the industry — from early-stage startups to Fortune 500 data teams — there is a clear architectural migration underway: away from vertically integrated, closed-garden platforms and toward open data architectures where storage, compute, and governance are independent, composable layers. The data stays on your infrastructure. The engines are chosen per workload. And the table format is an open standard that no single vendor controls.
This is not a speculative prediction. Snowflake and Databricks themselves are actively embracing Apache Iceberg and the Iceberg REST Catalog protocol, a tacit acknowledgement that the market is demanding openness. The question is no longer whether open data platforms will become the standard — it is how organizations navigate the transition, and what new challenges emerge when the platform is no longer a monolith.
The walled-garden model and its costs
Snowflake and Databricks built their businesses on a compelling premise: ingest your data into our system, and we will handle the rest. Storage, compute, optimization, governance, and query execution all lived inside one boundary. For teams without deep infrastructure expertise, this was transformative.
The trade-off was lock-in. With Snowflake, Snowflake-managed tables live in Snowflake's managed storage layer; moving large volumes out still means explicit export or externalization steps, and switching costs rise with data age and dependent objects. Databricks reduced friction by keeping many datasets in your cloud object storage (often as Delta Lake), but Unity Catalog and the broader product surface still create strong ecosystem gravity for governance, jobs, and notebooks.
The financial dynamics reinforce the pattern. Both platforms charge for compute using proprietary credit systems — Snowflake Credits and Databricks DBUs — that can be opaque to compare directly with raw cloud infrastructure line items. Object storage and open query engines are often materially cheaper per stored GB and per unit of compute for many analytic patterns, but realized savings depend on workload mix, egress, operations headcount, and contract terms—so treat migration ROI stories as directional, not guaranteed.
The deeper problem is architectural. When storage and compute are coupled — or when governance is tied to a single vendor's catalog — every new workload, every new team, and every new use case adds dependency on that platform. The platform becomes not just a tool but a constraint on how your data architecture can evolve.
Why the shift is happening now
Four forces are converging to make the open data platform not just viable but urgent.
Apache Iceberg matured. Iceberg solved the fundamental reliability gap that kept data lakes inferior to data warehouses. ACID transactions, schema evolution, hidden partitioning, time travel, and snapshot isolation — these are warehouse-grade features running on object storage. In the independent **2025 State of the Apache Iceberg Ecosystem** survey (fielded January 2026, published on DataLakehouseHub), 96.4% of respondents reported using Apache Spark with Iceberg, 60.7% OSS Trino, 32.1% Apache Flink, and 28.6% DuckDB — evidence that Iceberg functions as a shared substrate across engines, not a single-vendor runtime.
The Iceberg REST Catalog API standardized metadata access. Snowflake and Databricks have both shipped Iceberg REST catalog integrations (alongside other catalog options), enabling federation patterns where external engines and services can interoperate on Iceberg metadata using the same REST contract. In practice, teams can keep Iceberg files on S3 (or compatible object stores), register tables in REST-aware catalogs such as Apache Polaris, Apache Gravitino, Project Nessie, or Lakekeeper (among others), and query through engines that implement the contract—including Trino, Spark, DuckDB, Athena, Snowflake, and Databricks—subject to each engine's supported features and authentication model.
Economics forced the conversation. As data volumes grow into the petabyte range, the gap between durable object storage (for reference, AWS S3 Standard in common US regions often lists on the order of $0.023 per GB-month for the first storage tier—pricing and tiers change, so use the official calculator for your region) and metered proprietary analytics compute becomes impossible to ignore at scale. Finance and platform teams increasingly ask whether specific query tiers can run on open engines against the same Iceberg files without paying premium credits for every scan.
The urgent need for agentic AI readiness. AI agents are no longer a research curiosity — they are becoming primary consumers of enterprise data. Autonomous agents issue SQL iteratively inside tool-use loops, generate unpredictable query shapes, and require sub-second latency from tables that were designed for scheduled batch workloads. This creates a fundamentally new infrastructure contract: schema-discovery APIs so agents know what data exists before hallucinating table names, query guardrails that enforce cost ceilings and prevent PII leakage at machine speed, low-latency reads against well-compacted files, and stable routing endpoints that agents can call without per-session configuration. Closed platforms were not architected for this access pattern. Their query concurrency models, cost controls, and governance enforcement assume a human on the other side — not an autonomous loop issuing dozens of queries per reasoning step. Open data platforms, by contrast, allow organizations to insert purpose-built agent middleware (MCP interfaces, guardrail chains, adaptive routers) between the agent and the data without waiting for a single vendor to ship each capability. The infrastructure flexibility that decoupled storage and compute provides is exactly what makes it possible to build an agentic-AI-ready data layer today rather than waiting for a platform roadmap.
The architecture: storage as bedrock, engines as plugins
The open data platform inverts the traditional model. Instead of choosing a platform and conforming your data to it, you start with your data and plug in the capabilities you need.
Storage is the foundation. Data sits on Amazon S3, Google Cloud Storage, Azure ADLS, or on-premises object storage — in your account, under your control. The storage layer is durable, cheap, and universally accessible. It does not belong to any compute engine.
Iceberg is the contract. Apache Iceberg defines how data is organized, versioned, and accessed. Its metadata layer — manifest lists, manifest files, and data files — provides the ACID guarantees and schema management that engines need. Any engine that speaks Iceberg can read and write these tables without coordination with any other engine.
Engines are chosen per workload. Trino for interactive analytics. Spark for heavy ETL and batch processing. DuckDB for lightweight local queries. Flink for stream processing. Snowflake for BI workloads where its optimizer excels. Databricks for ML workflows and notebook-driven exploration. Each engine connects to the same tables, reads the same metadata, and operates independently.
Catalogs provide the registry. REST-compliant catalogs like Polaris, Gravitino, Nessie, and Lakekeeper serve as the metadata registry — the single source of truth for what tables exist, where they are stored, and how they are partitioned. Engines register against the catalog, discover tables, and coordinate writes through Iceberg's optimistic concurrency.
This architecture gives organizations something the walled-garden model struggles to match: the ability to adopt new engines without migrating the underlying files, to retire engines without rewriting the table format, and to benchmark alternative compute against the same Iceberg datasets—materially lowering switching friction compared with proprietary warehouse-native storage alone.
Where Databricks and Snowflake fit
The open data platform does not eliminate Databricks and Snowflake. It reframes them as components rather than platforms — powerful engines within a broader ecosystem, chosen when their specific strengths justify their cost.
Snowflake remains compelling for BI-heavy workloads where its query optimizer, caching layer, and concurrency handling outperform open alternatives. Teams running Tableau, Looker, or Power BI dashboards against high-concurrency query patterns will often find Snowflake delivers better price-performance than Trino for that specific use case. Snowflake's commitment to bidirectional Iceberg federation through its REST Catalog endpoint means it can participate in an open architecture without requiring data to live in Snowflake-proprietary storage.
Databricks brings differentiated value for ML and AI workloads where the integration between notebooks, MLflow, and Spark-native feature engineering is genuinely hard to replicate. For data science teams that need iterative, exploratory workflows on large datasets, the Databricks runtime offers optimizations that matter. Its full Iceberg support through Unity Catalog, including managed Iceberg tables readable by external engines, means Databricks workloads can coexist with open engine stacks on the same data.
The strategic insight is that both vendors have recognized the direction. Snowflake published "Open by Design" as an explicit company commitment. Databricks announced full Apache Iceberg support and extended Delta Sharing to serve data in Iceberg format. These are not defensive moves — they are acknowledgements that the future is multi-engine, and the vendors who participate in that future retain relevance. The ones who resist it do not.
The hard part: running an open data platform in production
The architectural elegance of decoupled storage and compute comes with an operational reality that most vendor marketing omits: when no single platform owns the full stack, nobody owns the maintenance either.
In a closed platform, compaction, snapshot management, storage optimization, and query tuning happen inside the vendor's managed service. You pay for it in your credit consumption, but it happens. In an open data platform, these responsibilities fall on your data platform team — and the operational surface area is significantly larger than most teams anticipate.
Observability across the stack. When queries hit Trino, Spark, and Snowflake against the same Iceberg tables, where do you look when latency degrades? Each engine has its own metrics surface, its own logging format, and its own definition of what constitutes a slow query. Cross-engine observability — understanding table health, query patterns, and resource consumption in one view — does not exist out of the box. You need unified telemetry that spans storage, catalogs, and every connected engine.
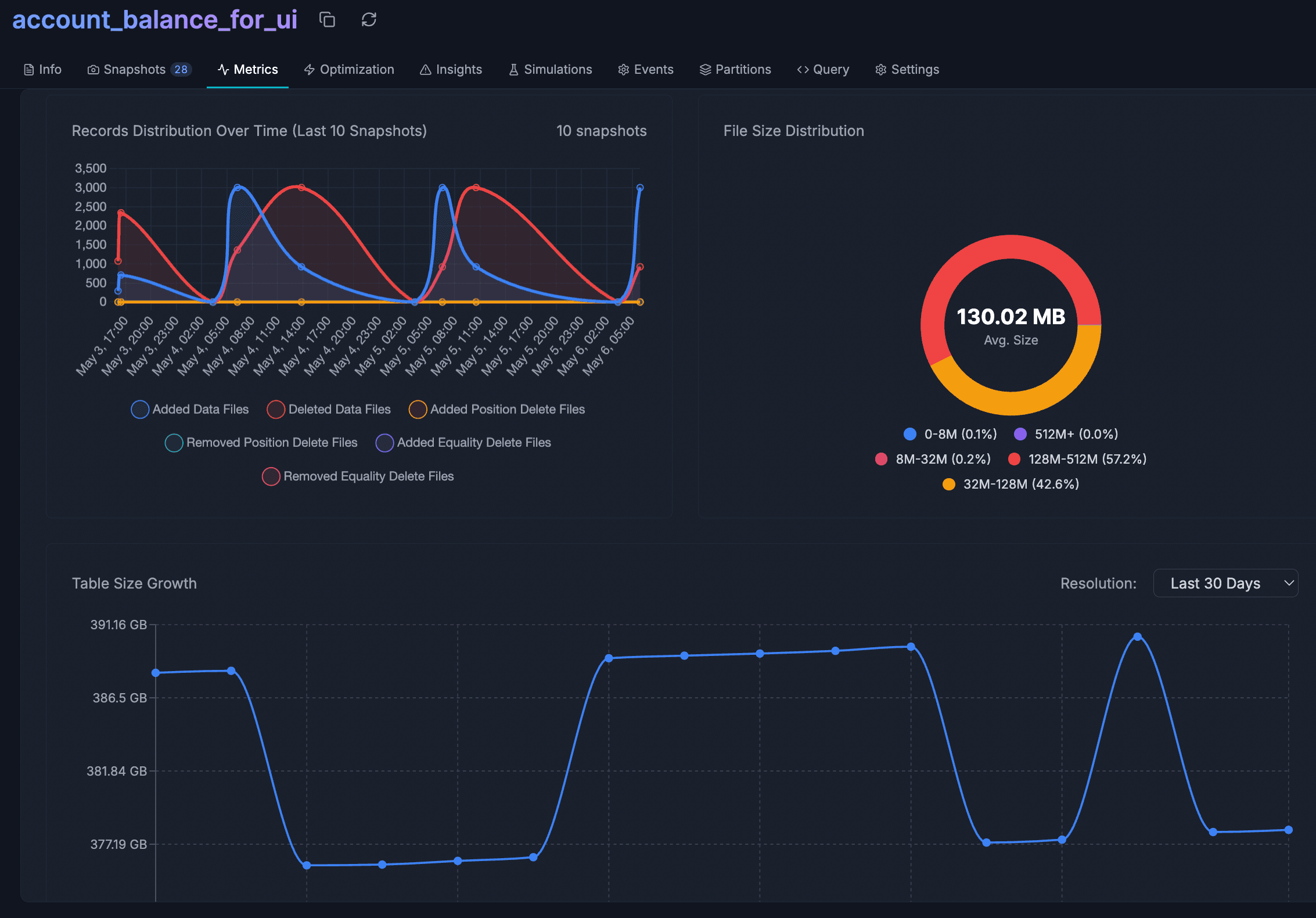
Table maintenance at scale. Iceberg tables degrade without continuous maintenance. Streaming pipelines create thousands of small files per day. Snapshots accumulate indefinitely if no one configures expiration. Orphan files from failed writes consume storage without serving any query. Manifests fragment until query planning takes longer than the scan itself. At 50 tables, you can manage this with scripts. At 500 tables across multiple catalogs, the manual approach breaks down completely.
Governance without a single control point. In a Snowflake-only world, access control lives in Snowflake. In a multi-engine open platform, you need governance that spans engines — row-level security, column masking, audit logging, and policy enforcement that works consistently whether the query comes from Trino, Spark, or a Python notebook. Achieving this with disparate engine-native controls is fragile and error-prone.
Agentic AI readiness. AI agents are becoming first-class consumers of data infrastructure: they issue SQL iteratively, generate unpredictable query patterns, and benefit from low-latency reads against tables that were originally sized for batch or dashboard traffic. Most enterprises are still early in running production agent loops directly on analytical lakes—yet the direction of travel is clear, and the safety and performance requirements differ from human-scale analytics. Agents need schema discovery interfaces, query guardrails, cost controls, and well-maintained table layouts that many legacy lake deployments never standardized.
Why autonomous management is necessary
The challenges above share a common thread: they are continuous, they compound, and they do not scale with human effort.
A data platform engineer can write a compaction script for a critical table. They cannot write and maintain compaction logic for 800 tables, each with different ingestion patterns, query workloads, file size distributions, and retention requirements. They cannot monitor cross-engine query performance across three engines and correlate it with table health metrics in real time. They cannot enforce consistent governance policies across every access path when new engines and new agent frameworks are added quarterly.
The operational complexity of an open data platform grows combinatorially — more tables multiplied by more engines multiplied by more consumers multiplied by more policies. Manual management hits a wall not because teams are not good enough, but because the problem exceeds human bandwidth. The solution has to be autonomous: systems that continuously monitor, decide, and act without requiring human intervention for every table, every operation, and every policy enforcement.
This is not aspirational. This is the minimum viable operating model for a production open data platform. Without autonomous management, the operational burden eventually pushes teams back toward managed platforms — trading architectural freedom for someone else owning the maintenance, and re-entering the lock-in cycle.
How LakeOps solves it
This is the problem LakeOps was built to solve: an autonomous control plane for open data platforms running Apache Iceberg.
LakeOps connects to your existing catalogs and object storage — AWS Glue, REST catalogs (Polaris, Gravitino, Nessie, Lakekeeper), S3 Tables — and begins continuous monitoring and optimization without requiring data movement, infrastructure changes, or code modifications. Setup takes roughly ten minutes.
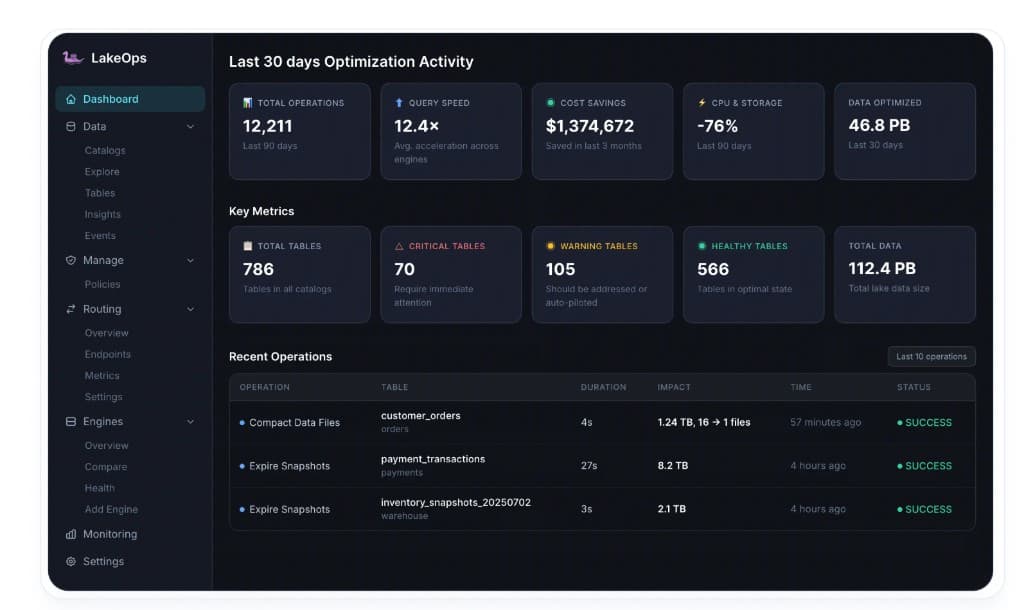
Full-stack observability. LakeOps provides unified telemetry across storage, engines, and catalogs from a single control plane. Table health classification, query latency tracking, throughput monitoring, error rates, and cost signals — all correlated across engines so you can see the full picture rather than stitching together engine-specific dashboards. Every table gets a health score based on file count, file size distribution, manifest fragmentation, snapshot depth, and orphan file accumulation.
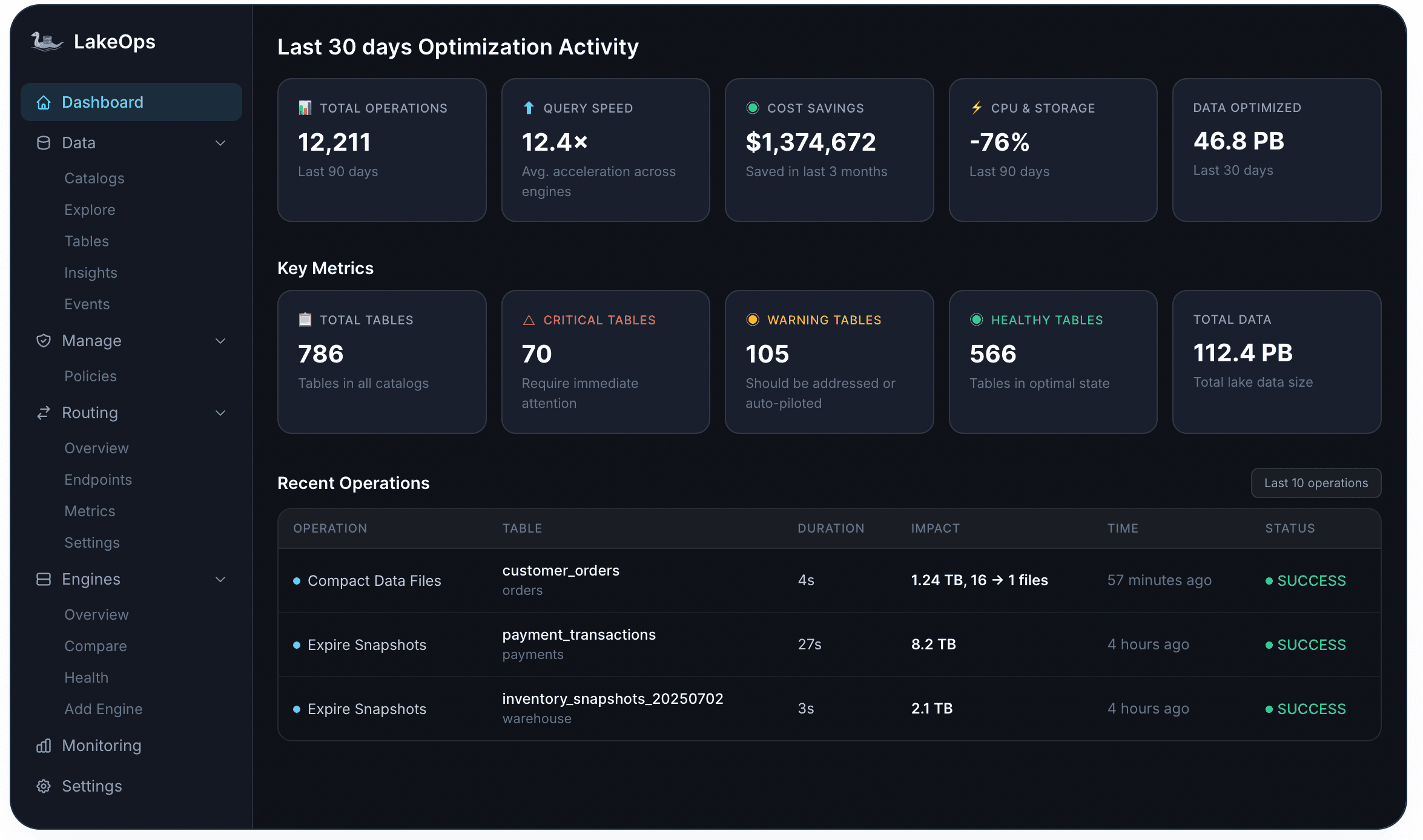
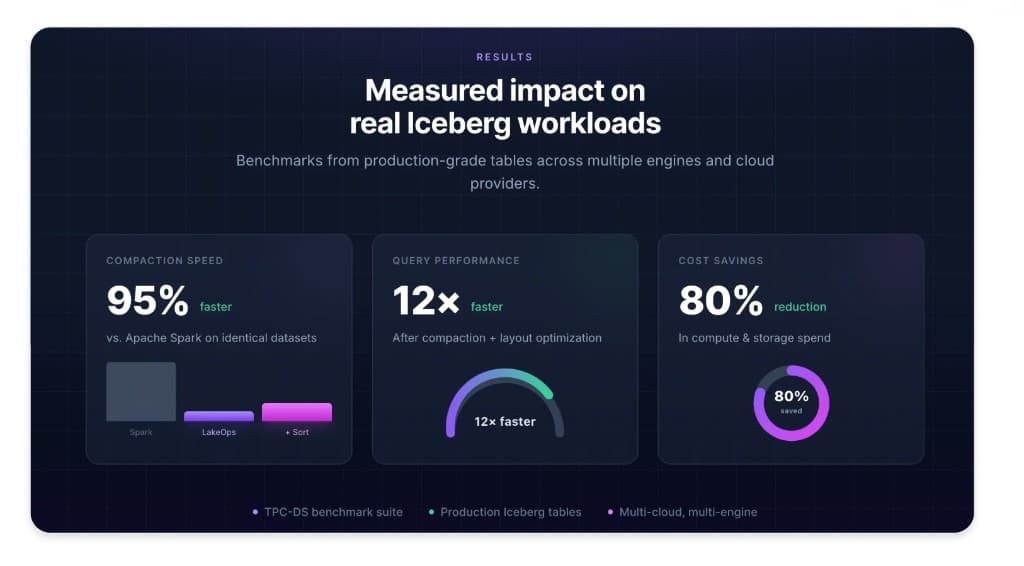
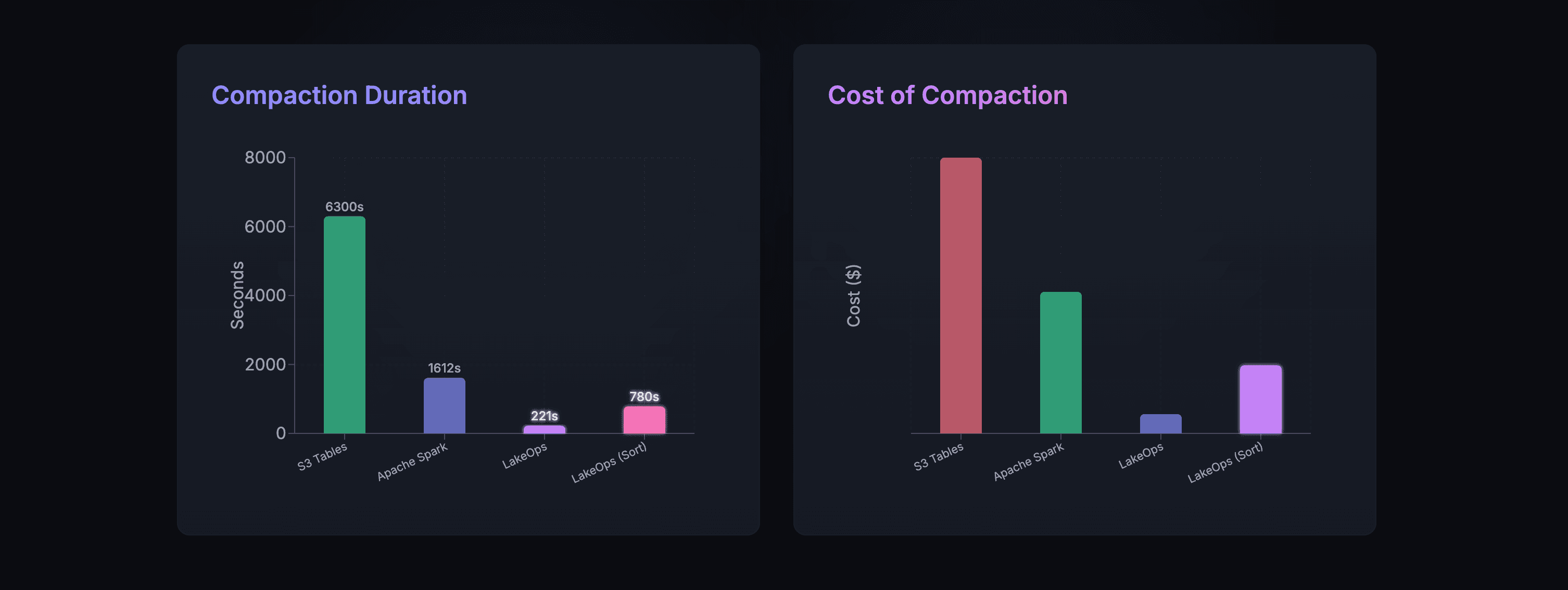
Autonomous table maintenance. Compaction, snapshot expiration, manifest rewrites, and orphan file cleanup run continuously in the background, driven by observed table health rather than static schedules. The compaction engine is built in Rust with Apache DataFusion. In LakeOps-published benchmarks on Medium (March 2026), authors report peak compaction throughput above 2,500 MB/s on production-scale Iceberg tables, up to about 99.8% file-count reduction on an extremely fragmented streaming table (tens of thousands of small files consolidated to dozens), and—on a ~1.2 TB table—Apache Spark failing with an out-of-memory error while LakeOps completed compaction in about eleven minutes on comparable hardware. Those are specific benchmark scenarios, not universal guarantees. LakeOps aims to avoid you operating separate Spark fleets just for that maintenance path.
Organization-wide policies. Define maintenance policies once and enforce them across every table in every catalog. Retention windows, compaction thresholds, file size targets, snapshot depth limits — all configurable per table, per namespace, or fleet-wide. Every operation is logged, auditable, and reversible.
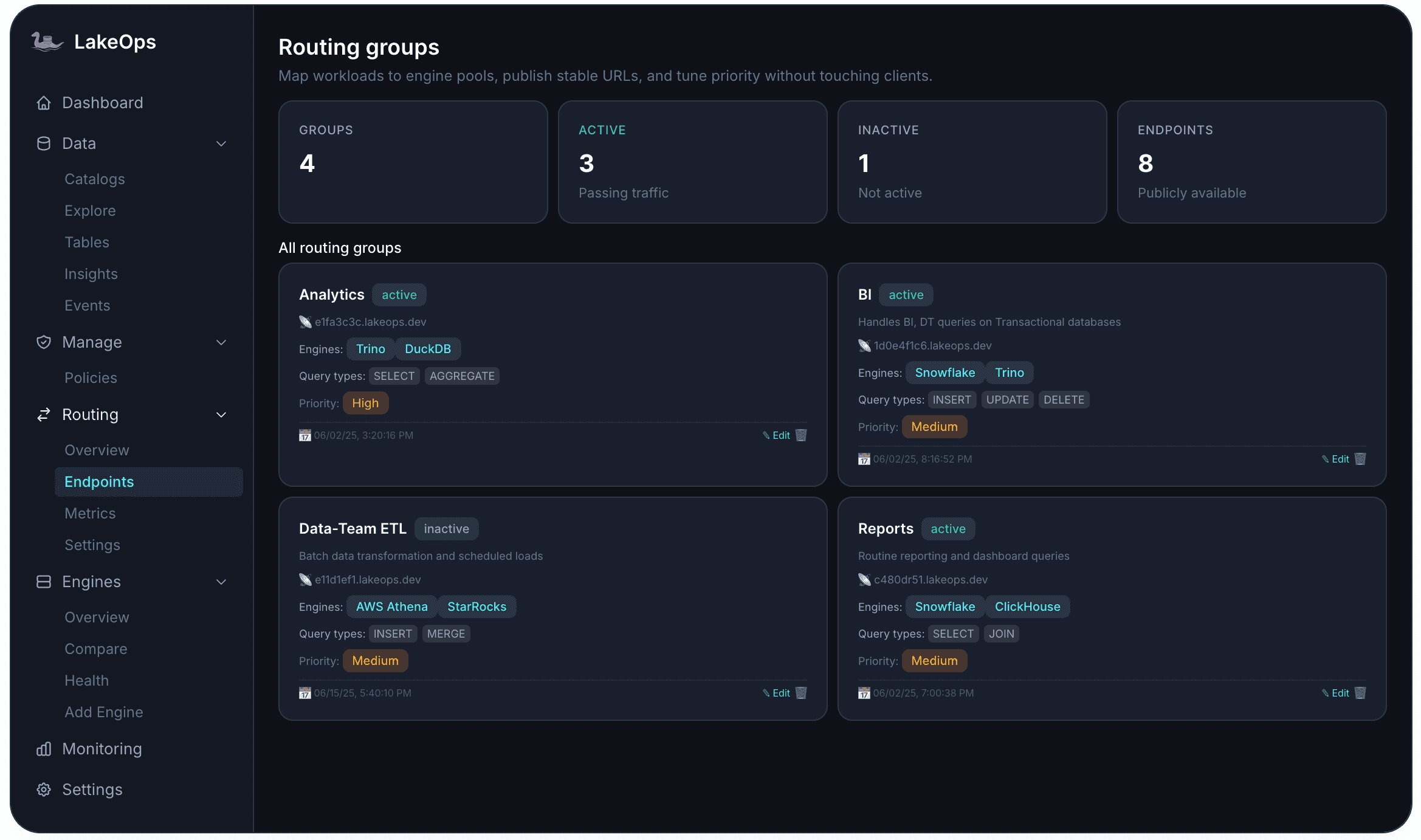
Multi-engine routing. Route queries across Trino, Spark, Snowflake, DuckDB, and more — optimized per workload for cost, latency, or throughput. Stable endpoint URLs that any consumer (human or agent) connects to, inheriting the full policy stack without per-consumer configuration.
Agentic AI enablement. An agent-native MCP interface with schema discovery, query guardrails (read-only enforcement, row limits, cost estimation, PII masking), and self-optimizing table structures that adapt to agent query patterns. The infrastructure layer that makes AI agents production-safe on your data lake.
LakeOps's public marketing on lakeops.dev displays aggregate, illustrative metrics (for example, large cumulative savings, multi-factor query speedup, and high automation coverage in demo-style dashboards). Those figures are vendor-presented, environment-specific, and not independently audited here—use them as a prompt to run your own proof of value on representative tables and contracts.
The future is open, composable, and autonomous
The transition from closed platforms to open data architectures is not a pendulum swing — it is a maturation of the industry. The data warehouse era solved the reliability problem. The data lake era solved the flexibility problem. The open data platform era solves the ownership problem: your data, your infrastructure, your choice of engines, with no single vendor holding the keys.
Databricks and Snowflake will remain important components in this ecosystem. Their engineering is excellent, and for specific workloads — high-concurrency BI, ML experimentation, notebook-driven analysis — they deliver value that justifies their cost. But they will increasingly operate as engines within an open architecture, not as the architecture itself.
The organizations that move fastest will be those that recognize the central challenge is not choosing the right table format or the right engine — that work is largely done. The challenge is operating the open platform in production: keeping hundreds of tables healthy across multiple engines, maintaining observability and governance without a monolithic control point, and preparing infrastructure for the autonomous agents that are already reshaping how data is consumed.
That operational challenge is exactly what LakeOps was built for. The open data platform is the future. Autonomous management is what makes it work.