Set up in 10 minutes · Works with your existing stack
Capabilities
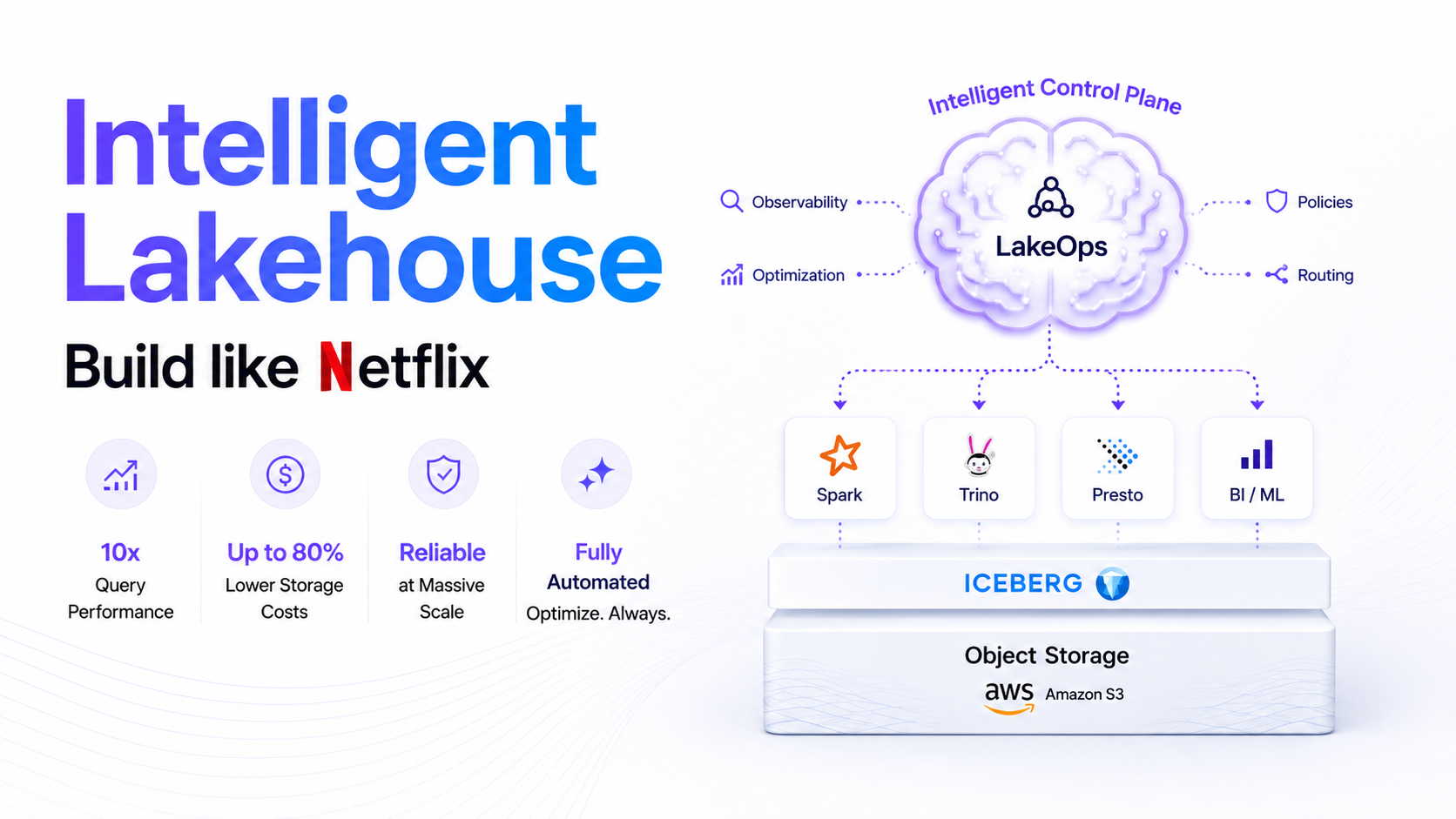
Autonomous Lakehouse orchestration and optimization
Every layer of your lakehouse — from compaction and metadata to engines, observability, and policy enforcement — managed from one control plane.
Compaction Benchmark1 TB TPC-DS
29× faster
Compaction Duration
Seconds
6300s
1612s
221s
780s
80006000400020000
S3 Tables
Apache Spark
LakeOps
LakeOps (Sort)
Cost of Compaction
Cost ($)
0
0
0
0
100%0
S3 Tables
Apache Spark
LakeOps
LakeOps (Sort)
Triggered by telemetry signals — not cron. Runs only when file health degrades.
Compaction
Intelligent compaction
Not just file merging — LakeOps analyzes which columns your queries actually filter, join, and group on, then organizes data files accordingly. The result: predicate pushdown and column pruning skip entire file groups, reducing I/O, query time, and compute cost across every engine reading the table. Powered by a Rust-based engine with Apache DataFusion — 95% faster and ~10x cheaper than Spark.
Query-aware: sorts data by the columns your workloads use most to cut query time and CPU
Triggered when needed; no cron jobs
Self-improving planner that adapts as query patterns change
38% small files — merging 970 → 87 at 512 MB target
then →Expire Snapshots
Cooling
Expire Snapshots
45%
154 snapshots, 62 past 30-day retention
then →Rewrite Manifests
Idle
Rewrite Manifests
18%
12 manifests — below threshold, waiting for compaction
then →Orphan Cleanup
Idle
Orphan Cleanup
8%
847 MB unreferenced — scheduled after expiration
Learning from telemetry
Query patterns
event_date, region
Top sort columns (Trino + Spark)
Improvement
12.4× faster
Avg query speed after optimization
Cycle
Self-tuning
Sort orders adapt as patterns change
Maintenance
Adaptive maintenance that learns
LakeOps continuously collects telemetry — file counts, partition health, snapshot velocity, delete ratios, manifest growth, and query patterns — and uses that signal to decide what to run, when, and in what order. Each operation's outcome feeds back into the next decision. The result is a coordinated maintenance loop that eliminates redundant work, adapts to changing workloads, and keeps every table in optimal shape without human intervention.
Scores every table on file health, snapshot growth, and manifest overhead — acts only when needed
Sequences operations so each step's output is the next step's clean input
Learns from query telemetry across all engines to optimize sort orders and compaction targets
684720182Mar 14, 08:00 PMAppend+3 data filesExpiring
Version control
Snapshot lifecycle management
Automated retention, expiration, and version history for every table. Set policies once — LakeOps expires old snapshots safely with full awareness of concurrent readers. Time-travel to any point, compare snapshots, and roll back without manual intervention.
Policy-based retention: set once, enforced continuously across every table and catalog
Concurrency-safe expiration that respects active readers and in-flight queries
Full version history with time-travel, snapshot comparison, and one-click rollback
Consolidate manifest files for faster query planning
Rewrite Position Deletes
Optimize position delete files to improve read performance
Compute Statistics (Puffin)
Calculate column stats to optimize query planning and pruning
Last rewrite: 487 → 12 manifests · Planner overhead reduced 62% · 2 min ago
Manifest & metadata optimization
Consolidate and rewrite manifest files so query planning stays fast at any scale. Smaller manifests mean faster planning and fewer metadata scans for Trino, Spark, Flink, and every engine that touches your lake. Includes position delete file optimization and Puffin statistics computation.
Rewrites manifests after compaction so planners scan fewer metadata files per query
Resolves position delete files to eliminate per-row filter overhead on reads
Computes Puffin column statistics for tighter partition and file pruning
Files only removed if unreferenced + older than threshold
Orphan file detection & cleanup
Detect and safely remove files no longer referenced by any table. Eliminate storage drift from failed jobs, aborted commits, and legacy tables. Configurable retention thresholds, catalog-wide or per-table scope, and scheduled execution — reclaim capacity without risking data integrity.
Age-threshold safety: only removes files unreferenced for 7+ days — no risk to in-flight jobs
Runs after snapshot expiration so newly dereferenced files are caught in the same sweep
Catalog-wide or per-table scope with full audit trail of every file removed
Continuous analysis of table structure, file health, and optimization opportunities. Monitor active engines, query latency, throughput, and error rates. Cross-system telemetry from S3, GCS, ADLS, and every engine — view, alert, and act from one place.
Proactive insights surface file-health issues, partition skew, and manifest bloat before they impact queries
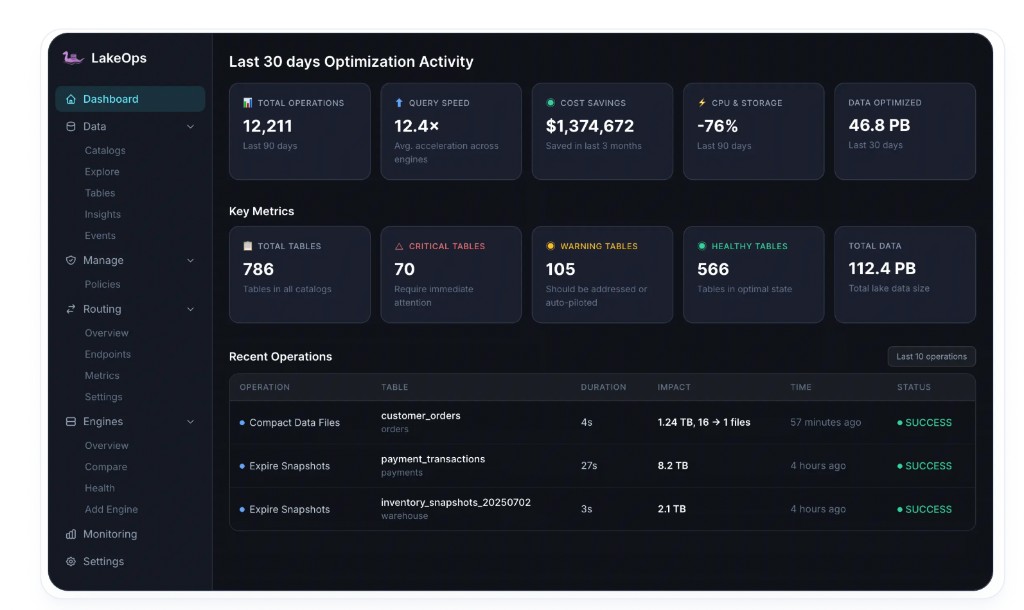
Unified event history for every operation — compaction, expiration, orphan removal — with duration, impact, and status
Cross-engine telemetry: one view across Trino, Spark, Snowflake, Athena, DuckDB, and Flink
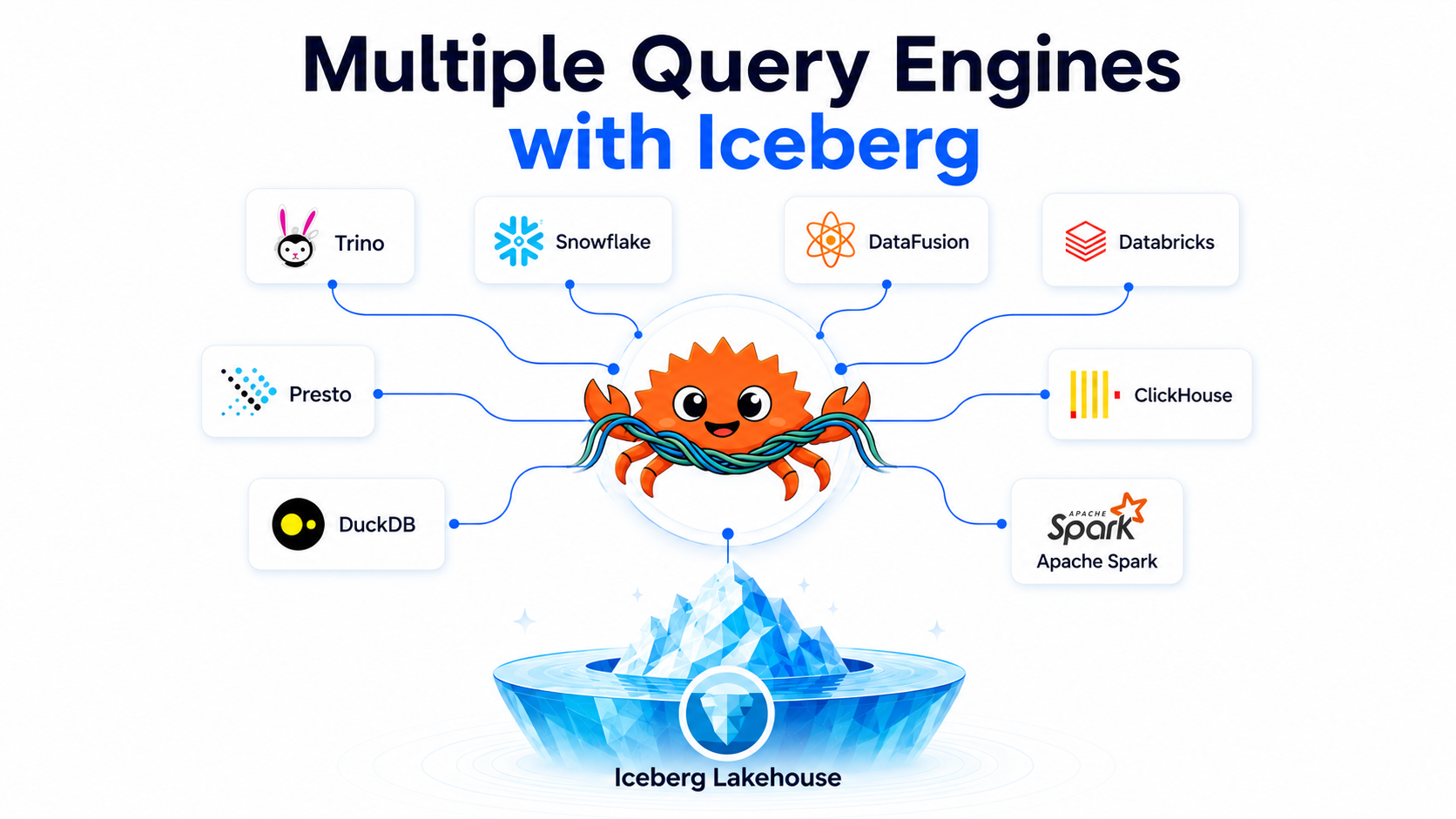
Connect Trino, Spark, Snowflake, Athena, DuckDB, and Flink to one routing layer. Intelligent query routing optimizes for cost, latency, or throughput automatically. Compare engine performance, monitor health, and add new engines — all without engine-specific scripts or duplicate tooling.
One SQL endpoint for all engines — route by cost, latency, or workload type automatically
Side-by-side engine comparison on the same queries to find the best fit for each workload
Add or remove engines without changing application code or connection strings
Hashes sensitive columns before results reach the model
HumanApproval
Pauses high-stakes operations for review
Agent query telemetry feeds back into compaction and sort-order decisions
Agentic AI
Agentic AI enablement
Built for AI and ML pipelines — optimized metadata, layout, and table structure for agents, feature stores, and autonomous data workflows. Run simulations on file layout changes before applying them. Fast, consistent access to table state and history so AI pipelines get the data they need without extra glue.
MCP interface with schema discovery, async queries, and PostgreSQL/MySQL/Arrow Flight wire compatibility
Layered guardrails: ReadOnly, CostEstimate, PIIMask, and HumanApproval — configurable per agent session
Closed-loop optimization: agent query telemetry feeds back into compaction and sort-order decisions
Define and enforce compaction, retention, orphan cleanup, and maintenance policies across catalogs and tables. Set schedules, priorities, and target scopes — then let LakeOps execute continuously. Every policy is auditable, versioned, and controllable with one toggle.
One-toggle policies for compaction, retention, orphan cleanup, and manifest optimization
Catalog-wide or per-table scoping with priority levels and cron-based scheduling
Full audit trail: every policy execution logged with duration, impact, and outcome