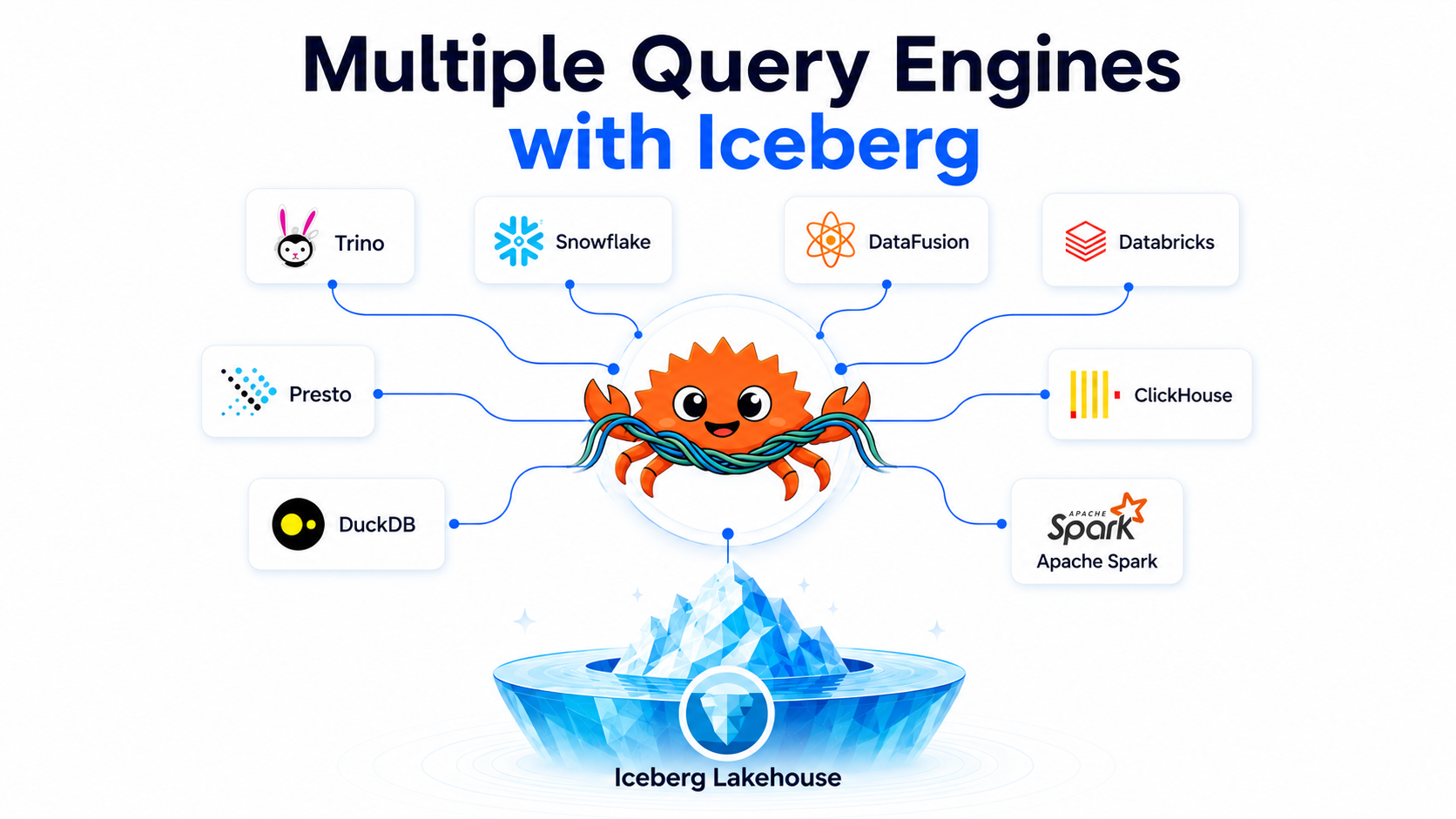
Apache Iceberg
Managed Iceberg in 2026: Autonomous Data Lake
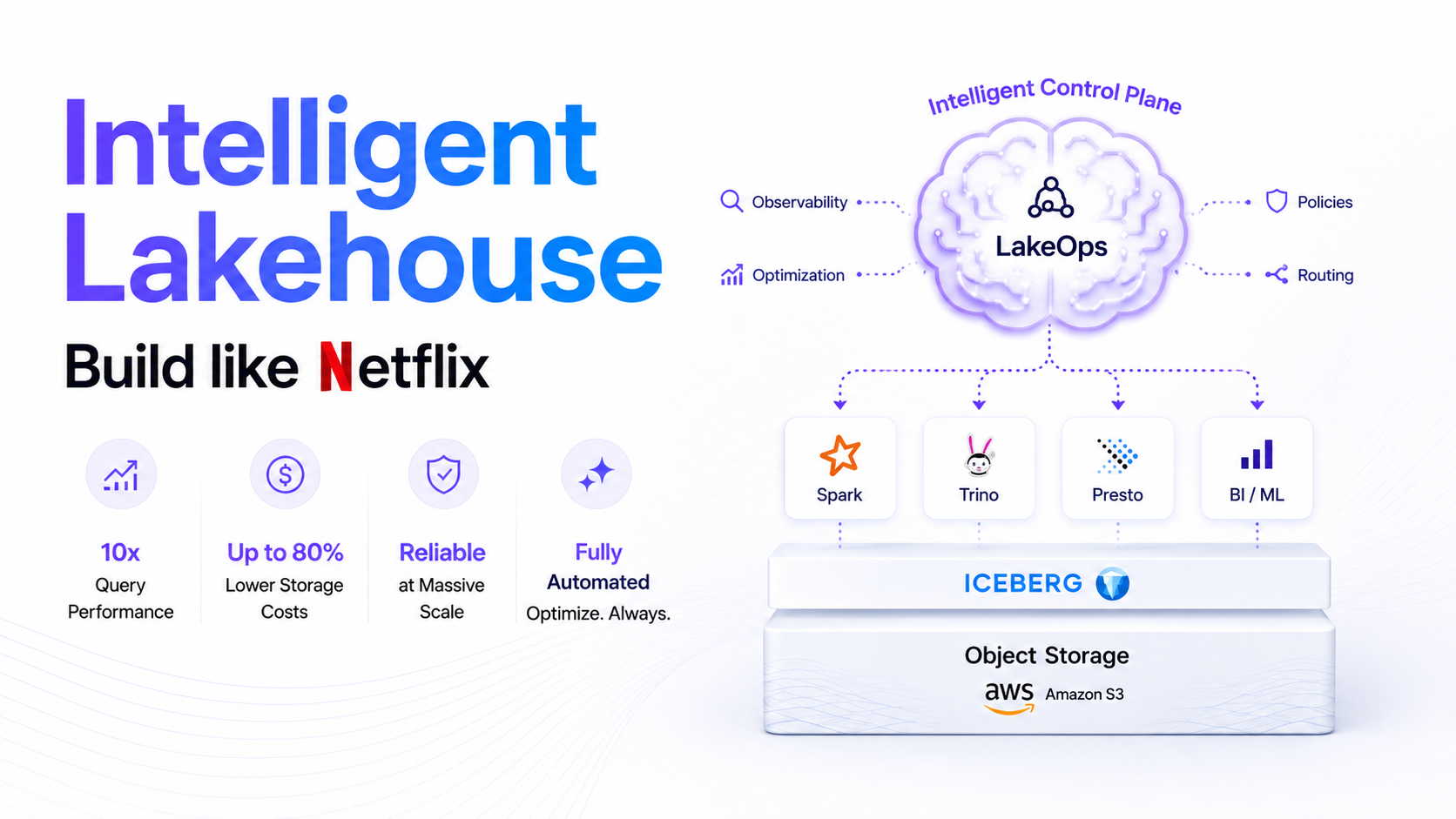
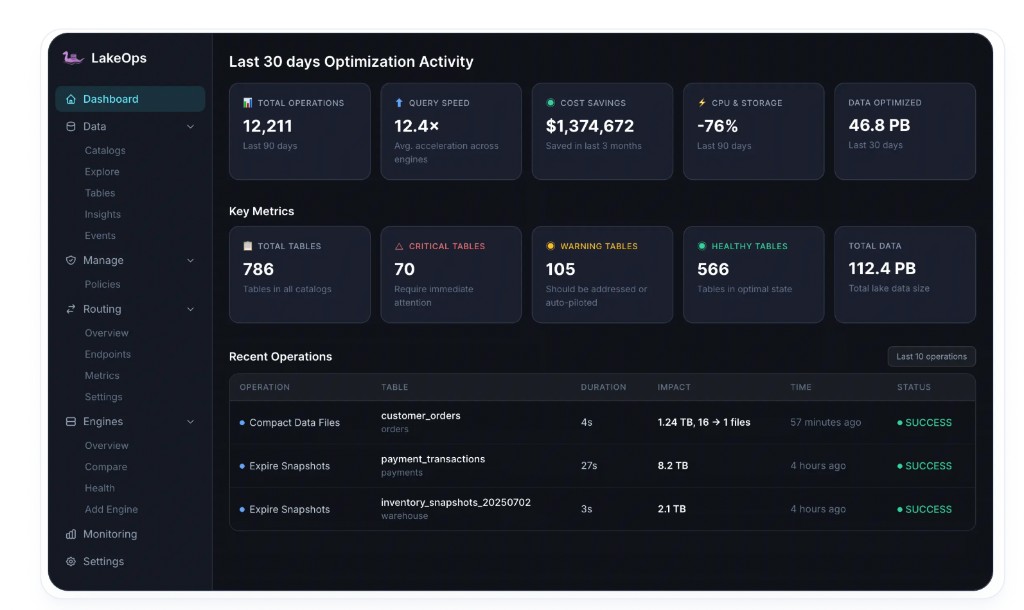
Iceberg tables degrade silently — small files pile up, snapshots bloat metadata, and query latency creeps higher. A breakdown of the nine components every production data lake needs to stay healthy.